카테고리 없음
Ensemble
dev-bleck
2022. 9. 13. 14:44
# 타이타닉 데이터 불러오기
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
df = sns.load_dataset('titanic')
cols = ["age","sibsp","parch","fare"] # 숫자니까 바로 사용
features = df[cols] # 피쳐
target = df["survived"] # 정답값
# one hot encoding
cols = ["pclass","sex","embarked"] # 범주형
enc = OneHotEncoder(handle_unknown='ignore')
tmp = pd.DataFrame(
enc.fit_transform(df[cols]).toarray(),
columns = enc.get_feature_names_out()
)
features = pd.concat([features,tmp],axis=1)
# 나이 결측치 채우기
features.age = features.age.fillna(features.age.median())
# scaling
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
features.loc[:,features.columns] = scaler.fit_transform(features)
# holdout
SEED = 42
x_train, x_valid, y_train, y_valid = train_test_split(features, target, random_state = SEED, test_size = 0.2)
x_train.shape, x_valid.shape, y_train.shape, y_valid.shape앙상블 학습(Ensemble Learning)
- 기계학습에서 여러개의 개별모델의 예측을 결합함으로써 보다 정확한 예측을 도출하는 기법
앙상블 모델
Random Forest
- 랜덤하게 일부 샘플(행)들과 일부 피쳐들을 뽑아서 여러개의 트리를 만들어서 앙상블 하는 모델
- 배깅(Bagging) 방식을 이용
- Bagging(Bootstrap Aggregation) : 샘플을 랜덤하게 여러번 뽑아 각 모델에 학습시켜 결과물을 집계하는 방법

from sklearn.ensemble import RandomForestClassifier
hp = {
"random_state" : SEED,
"max_features" : "sqrt", # None을 줄 경우 전체 features 사용
"n_estimator" : 100, # 내부 트리 개수. 모델마다 의미하는 바가 다르니 주의.
"max_depth" : 10,
"min_samples_split" : 10,
"min_samples_leaf" : 3
}
model = RandomForestClassifier(**hp)
model.fit(x_train, y_train)
pred = model.predict_proba(x_valid)[:,1]
roc_auc_score(y_valid, pred)
>>> 0.8952380952380953# Bagging
from sklearn.ensemble import BaggingClassifier
from sklearn.linear_model import LogisticRegression
hp = {
"random_state" : SEED,
"base_estimator" : LogisticRegression(random_state = SEED), # None이면 결정트리를 사용
"n_estimators" : 100, # base_estimator 개수
"max_features" : 0.5 # 추출할 샘플 비율
}
model = BaggingClassifier(**hp)
model.fit(x_train, y_train)
pred = model.predict_proba(x_valid)[:,1]
roc_auc_score(y_valid, pred)
>>> 0.8698841698841698Voting
- 여러 모델들의 예측값을 투표방식(hard) 또는 평균방식(soft)으로 앙상블
from sklearn.neural_network import MLPClassifier
from sklearn.ensemble import VotingClassifier
estimators = [("mlp", MLPClassifier(max_iter = 1000, random_state = SEED)),
("lr", LogisticRegression(random_state = SEED)),
("rf", RandomFroestClassifier(random_state = SEED))]
hp = {
"estimators" : estimators,
"voting" : "soft"
}
model = VotingClassifier(**hp)
model.fit(x_train, y_train)
pred = model.predict_proba(x_valid)[:,1]
roc_auc_score(y_valid, pred)
>>> 0.9063063063063064# roc_auc_score가 아닌 f1-score 사용
# voting 방식 hard로 변경
from sklearn.metrics import f1_score
estimators = [("mlp", MLPClassifier(max_iter = 1000, random_state = SEED)),
("lr", LogisticRegression(random_state = SEED)),
("rf", RandomForestClassifier(random_state = SEED))]
hp = {
"estimators" : estimators,
"voting" : "hard"
}
model = VotingClassifier(**hp)
model.fit(x_train, y_train)
pred = model.predict(x_valid)
f1_score(y_valid, pred)
>>> 0.7659574468085106Stacking
- 여러 모델의 예측값을 최종 모델(메타 모델)에 학습데이터로 사용해서 예측하는 방법
- 과적합 방지를 위해 내부적으로 CV(Cross Validation)을 진행
from sklearn.ensemble import StackingClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
estimators = [("knn"m KNeighborsClassifier(n_neighbors = 10, weights = "distance")),
("dt", DecisionTreeClassifier(max_depth = 3, random_state = SEED)),
("rf", RandomForestClassifier(random_state = SEED))]
hp = {
"estimators" : estimators,
"final_estimator" : LogisticRegression(random_state = SEED)
}
model = StackingClassifier(**hp, n_jobs = -1) # n_jobs = -1 : 모든 cpu 활용
model.fit(x_train, y_train)
pred = model.predict_proba(x_valid)[:,1]
roc_auc_score(y_valid, pred)
>>> 0.8820463320463321Gradient Boosting
- 트리 기반 부스팅 앙상블 모델
- 머신러닝 알고리즘 중 가장 예측 성능이 높고, 인기있는 알고리즘
- Boosting
- 약한 모델을 결합하여 강한 모델을 만드는 과정
- Bagging과 다른 점은 순차적으로 모델을 만들어 각 모델의 예측결과를 결합

# 타이타닉 데이터 백업
data_backup = x_train.copy(), x_valid.copy(), y_train.copy(), y_valid.copy()
# 당뇨병 데이터 불러오기
from sklearn.datasets import load_diabetes
diabetes = load_diabetes()
data = diabetes.data
target = diabetes.target
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error
# DecisionTreeRegressor
# holdout
x_train, x_valid, y_train, y_valid = train_test_split(data, target, random_state = SEED)
# hyperparameter
hp = {
"max_depth" : 2,
"random_state" : SEED
}
# weak 1
weak1 = DecisionTreeRegressor(**hp)
weak1.fit(x_train, y_train)
pred = weak1.predict(x_train) # 잔차를 구하기 위해서 학습데이터를 넣음
# weak 2
residual = y_train - pred # 잔차를 정답값으로 사용
weak2 = DecisionTreeRegressor(**hp)
weak2.fit(x_train, residual)
pred = weak2.predict(x_train)
# weak 3
residual = residual - pred
weak3 = DecisionTreeRegressor(**hp)
weak3.fit(x_train, residual)
pred = weak1.predict(x_valid) + weak2.predict(x_valid) + weak3.predict(x_valid)
mean_squared_error(y_valid, pred) ** 0.5 # RMSE
>>> 61.872491186086826
# GradientBoostingRegressor
# n_estimators : 부스팅 단계 / learning_rate : 이전 잔차를 얼마나 반영할지에 대한 비율
gbr = GradientBoostingRegressor(**hp, n_estimators = 3, learning_rate = 1.0)
gbr.fit(x_train, y_train)
pred = gbr.predict(x_valid)
mean_squared_error(y_valid, pred) ** 0.5 # RMSE
>>> 61.872491186086826# 백업해둔 타이타닉 데이터 복원
x_train, x_valid, y_train, y_valid = data_backup
from sklearn.ensemble import GradientBoostingClassifier
hp = {
"random_state" : SEED,
"max_depth" : 2,
"n_estimators" : 100 # 수행할 부스팅 단계 수
}
model = GradientBoostingClassifier(**hp)
model.fit(x_train, y_train)
pred = model.predict_proba(x_valid)[:,1]
roc_auc_score(y_valid, pred)
>>> 0.8911196911196911XGBoost
- 병렬처리가 불가능한 GBM의 단점을 보완
- GPU 지원
- 내장된 교차검증, 결측치 처리 등의 부가기능 지원
- GBM 보다 속도 향상
- GBM 보다 뛰어난 과적합 방지
from xgboost import XGBClassifier, plot_importance
hp = {
"random_state" : SEED,
"max_depth" : 2,
"n_estimators" : 100 # 수행할 부스팅 단계 수
}
model = XGBClassifier(**hp)
model.fit(x_train, y_train)
pred = model.predict_proba(x_valid)[:,1]
roc_auc_score(y_valid, pred)
>>> 0.8868082368082368# 중요도 시각화
import matplotlib as plt
plot_importance(mode)
plt.show()
# model tree화
from xgboost import to_graphviz
to_graphviz(model)
LightGBM(LGBM)
- XGBoost와 마찬가지로 병렬 처리 및 GPU 지원
- XGB보다 학습에 걸리는 시간이 적음
- XGB보다 메모리를 훨씬 적게 사용
from lightgbm import LGBMClassifier, plot_importance
hp = {
"random_state" : SEED,
"max_depth" : 2,
"n_estimators" : 100, # 수행할 부스팅 단계 수
}
model = LGBMClassifier(**hp)
model.fit(x_train, y_train)
pred = model.predict_proba(x_valid)[:,1]
roc_auc_score(y_valid, pred)
>>> 0.8821106821106821# 중요도 시각화
plot_importance(model)
plt.show()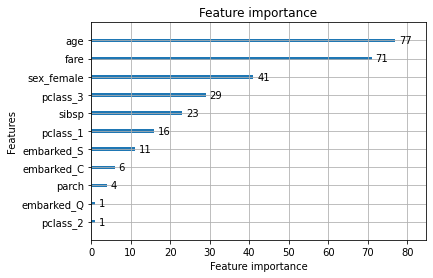
# model tree화
from lightgbm import create_tree_digraph
create_tree_digraph(model)
Catboost
- 범주형 변수에 대하여 강력한 성능을 보여주는 GBM 기반 모델
- 수치형 변수를 범주형 변수로 만들어서 사용하면 좋을듯?
- 범주형 변수가 많을 경우 높은 성능과 함께 속도가 lightgbm보다 빠름
- 수치형 변수가 많을 경우 매우 느림
- 범주형 변수를 인코딩하지 않고 넣어도 됨
pip install catboost
from catboost import CatBoostClassifier
hp = {
"random_state" : SEED,
"max_depth" : 2,
"n_estimators" : 100, # 수행할 부스팅 단계 수
"verbose" : 0 # 부스팅 단계 출력 안보이게 하기
}
model = CatBoostClassifier
model.fit(x_train, y_train)
pred = model.predict_proba(x_valid)[:,1]
roc_auc_score(y_valid, pred)
>>> 0.8787001287001287728x90